|
|
Home > Problems > Chapter 13
1. Below is a small hypothetical data set of microarray expression values. The rows are genes A, B, C, and D on the microarray and the columns are observed variations in the transcription of these genes; e.g., the columns could represent the gene expression profile of a type of cancer cell, genes expressed in one part of the cell cycle, or genes expressed at different times after a particular treatment given to cells. Assume that these data have been corrected for sources of variation in the data as we have described in the chapter. To simplify the work, we will let the numbers be the ratio of expression under a given condition to that under a control condition as in a spotted cDNA microarray experiment.
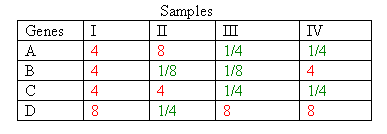
- Convert the odds scores in the above table to log odds scores to the base 2 and make a new table of these log odds scores below.
Log odds scores

- Calculate the Pearson correlation coefficient (see Table 13.7) between all gene combinations and between all sample combinations and enter the values into the following tables except where an x is shown. Note that the between-genes analysis is asking, "Are these genes following a similar expression pattern in the samples?" and the between samples analysis is asking, "For these two samples, is the gene expression pattern similar?"
Pearson correlation coefficients
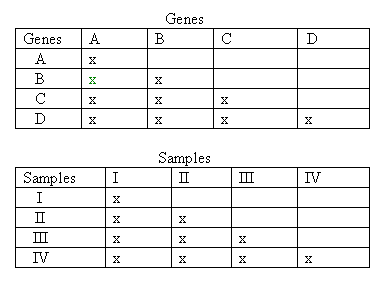
- Calculate the distances between genes and samples using the absolute value of the correlation coefficient as shown in Table 13.7.
Distances based on correlation coefficient
- Which gene pairs and sample pairs show the greatest similarity on the basis of the above distance scores?
- Calculate the Euclidean distance between all genes and sample combinations based on the log odds scores given above. The calculation is an extension of calculating the hypotenuse on a right-angled triangle. The differences between each pair of measurements are subtracted and the result is squared. The squares are added and the square root of the sum is the Euclidean distance.
Euclidean distance

- Which genes and sample combinations have the smallest Euclidean distances?
- How do the closest gene and sample combinations in part f compare with those found in part d using the absolute value of the correlation coefficient to calculate a distance?
- Produce a hierarchical clustering diagram of the samples only based on these Euclidean distances. Use the same distance method that was used for producing a phylogenetic tree in Problem 1 of Chapter 7.
- Suppose that samples I and II are from diseased tissue and that III and IV are from normal tissue (i.e., that the samples are from known classes), and that we want to find a test or classifier that will tell whether a new sample "X" belongs to one class (Diseased) or the other (Normal). Compare the samples on a plot of log odds scores of each combination of gene pairs and make a judgment call as to which gene pair provides the best classifier. For example, plot the log odds scores of the four tissue samples on the following graph that shows the gene A value on the vertical axis and the gene B on the horizontal axis. Draw another graph for the A, C gene combination as shown. On the basis of these two graphs, which gene combination best discriminates between diseased and normal samples?
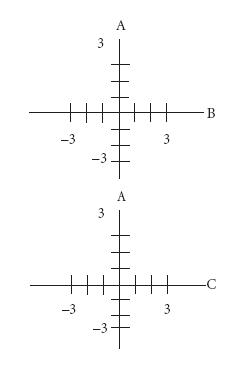
- What approximate values should unclassified sample "X" have to be classified as normal or diseased?
- Are any other gene pairs useful for classifying "X"?
|
|
|
| © 2004 by Cold Spring Harbor Laboratory Press. All rights reserved. |
 |
| No part of these pages, either text or image, may be used for any purpose other than personal use. Therefore, reproduction, modification, storage in a retrieval system, or retransmission, in any form or by any means, electronic, mechanical, or otherwise, for reasons other than personal use, is strictly prohibited without prior written permission. |
|
|
|
